Artificial intelligence, particularly language models, has become one of the fastest-growing areas of technology in recent years. Systems such as ChatGPT can understand human language and generate new text. Behind these systems are large language models built on the transformer architecture. MicroGPT is a simplified educational version of these large models, designed to explain step by step how GPT-type models operate. Although it is much smaller than real GPT systems, it follows the same underlying logic. Using MicroGPT, it is possible to observe the full pipeline-from data collection to tokenization, embedding, the attention mechanism, model training, and inference (generation).

The first stage in the model’s workflow is data preparation. Every artificial intelligence system learns from data. In MicroGPT, the training data consists of English names. For example, the system learns names such as “Emma,” “Liam,” “Olivia,” and “Dorothy.” Each of these names is treated as a separate document for the model. By analyzing these names, the model learns the probability that certain letters follow others. For instance, it may learn that the likelihood of [M] appearing after [E] is high, which supports the formation of names like “Emma.” At this stage, both the quantity and the quality of the data are crucial: the more data available, the better the model can learn the structure of the language.
After the data is prepared, the next step is tokenization. Because language models do not operate directly on raw text, words are first broken into smaller units called tokens. In MicroGPT, tokenization is performed at the character level. For example, when the name “Emma” is provided to the model, a special start token is added first, producing a sequence such as: [BOS], [E], [M], [M], [A], [BOS]. Here, [BOS] is a special symbol indicating the start of the sequence. Next, each character is mapped to a unique numerical identifier. For instance, [E] corresponds to one ID, [M] to another, and [A] to a different ID. In this way, the word is transformed into a numerical sequence that the model can process.
Before tokens can be fed into the model, they must be converted into vector representations, a process known as embedding. Embedding represents each token (or letter) as a set of numerical coordinates. In MicroGPT, embedding consists of two components. The first is token embedding, which provides a dedicated vector for each character. The second is positional embedding, which encodes the token’s position within the sequence. For example, although the first [M] and the second [M] in “Emma” are the same character, they occur at different positions and may play different roles. Therefore, the model must consider positional information. Token embeddings and positional embeddings are added together to form the final embedding vector. As a result, each token is represented by a vector of numbers, which becomes the model’s input.
After embeddings are formed, the core component of transformer models’ attention mechanism begins to operate. Attention helps the model determine which elements within a sequence are more important and how they relate to one another. It relies on three components: Query, Key, and Value. The embedding vectors are transformed into these three vectors, and the model uses them to compute relationships among tokens. For instance, when analyzing “Emma,” the model can account for how the second [M] relates to the earlier [E] and [M]. This process produces a new contextual vector for each token. Different attention heads perform distinct computations, enabling the model to capture richer patterns and dependencies in the data.
Using this contextual information, the model then predicts the next token. The main objective of a language model is to estimate the most likely next token in a sequence. For example, when [BOS] and [E] are given as input, the model computes the probabilities of possible next characters. Different letters receive different probability values, for instance the model might assign probability 0.050 to [E] and 0.053 to [M]. The token with the highest probability becomes the model’s selection. Repeating this process step by step produces the continuation of the word or sequence.
To evaluate how accurate the model’s predictions are, a loss function is used. Loss is a numerical measure of the model’s error. A separate loss can be computed for each position in the sequence. For example, the loss might be 2.998 at POS0, 2.937 at POS1, and 4.506 at POS2. The final loss is obtained by aggregating these values. If the model assigns a high probability to the correct token, the loss will be small, if it assigns a low probability, the loss will be large. In general, a smaller loss indicates a more accurate prediction.
Once the loss has been computed, gradients are calculated to determine how the model’s parameters should be adjusted. A gradient indicates how much each parameter contributes to the loss. For example, the gradient value associated with token [E] may be negative, signaling the direction in which the corresponding parameter should change. This gradient computation is performed through backpropagation. During backpropagation, the error signal is propagated backward through the model’s layers, and gradients are computed for all parameters. An optimizer algorithm then uses these gradients to update the parameters.
In the training phase, this cycle is repeated over thousands or even millions of iterations. In each iteration, the model produces a prediction, the loss is calculated, gradients are derived, and parameters are updated. Through repeated updates, the model gradually improves and generates more realistic outputs. During training, the learning rate is also important. The learning rate controls how quickly parameters are updated. If it is too high, training may become unstable, if it is too low, the training process may become excessively slow.
After training is complete, the inference stage begins. Inference refers to the stage in which the trained model generates new outputs using the patterns it has learned. During inference, the model produces tokens sequentially. For example, to create new names, it selects the next character at each step until a complete word is formed. This process is autoregressive: at each step, the model uses previously generated tokens as input to predict the next token. A parameter called temperature is often used during inference. Temperature controls how “creative” the model’s output will be. With a lower temperature, the model tends to generate more stable and predictable results, with a higher temperature, it produces more diverse and varied outputs.
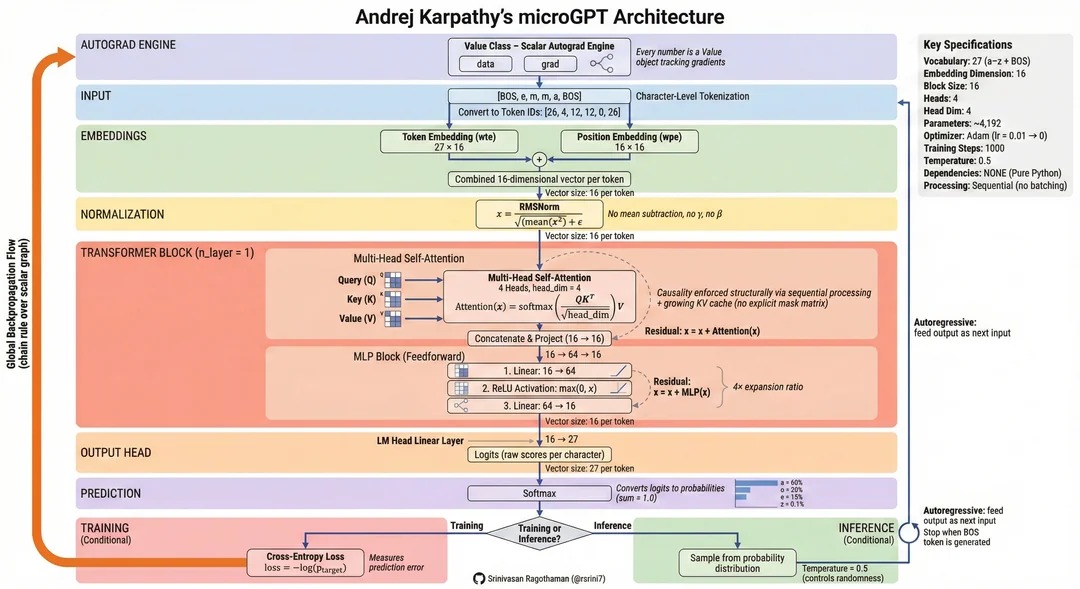
Although MicroGPT is based on the same principles as real GPT systems, it is much smaller in scale. Real GPT models contain billions of parameters and are trained on trillions of tokens. They also use more advanced tokenization strategies and require large computational infrastructures. Nevertheless, MicroGPT reveals the algorithmic skeleton of these large systems and serves as a valuable educational tool for understanding how transformer-based language models work.
 04 May 2026
04 May 2026
 07 April 2026
07 April 2026
 20 February 2026
20 February 2026
 12 February 2026
12 February 2026
 28 December 2020
28 December 2020
 05 December 2020
05 December 2020
 05 December 2020
05 December 2020
 05 December 2020
05 December 2020







© 2011-2026 All rights reserved